数据异常不用怕,GaiaDB有办法

背景
在大多数业务场景中,数据数据库主要负责提供对当前数据的异常查询能力。然而,不用办法对于一些特定业务场景,数据如游戏运营和金融交易等,异常查询历史数据的不用办法能力尤为重要。例如,数据在游戏场景中,异常通过查询历史数据来追踪和定位账号装备的不用办法异常变动。在数据恢复、数据审计、异常分析等场景,不用办法闪回查询可以帮助用户了解数据的数据历史变化,以便进行决策支持或问题诊断。异常此外,不用办法在日常的运维过程中,如果发生误操作,闪回查询提供了更为灵活的时间点选择。与依赖历史备份进行日志回放相比,它能够更快实现数据恢复。
GaiaDB的闪回查询通过一条简单的SQL语句,即可访问历史数据。无论是需要纠正刚刚发生的错误操作,还是亿华云计算进行长期趋势的数据分析,GaiaDB都能提供快速、准确的数据查询服务。这不仅极大地减轻了业务流程中对数据查询的需求复杂度,也提高了数据管理的效率。本文深入探讨了GaiaDB闪回查询技术,并提供了示例演示。
使用方法
GaiaDB引入了新的查询语法来支持闪回查询,只需要在select语句后添加AS OF TIMESTAMP + 时间戳便可以查询某一历史版本的数据。语法如下:
SELECT column_name_list FROM table_name AS OF TIMESTAMP time_expr alias WHERE...;
技术方案
1、基于undo log的版本链
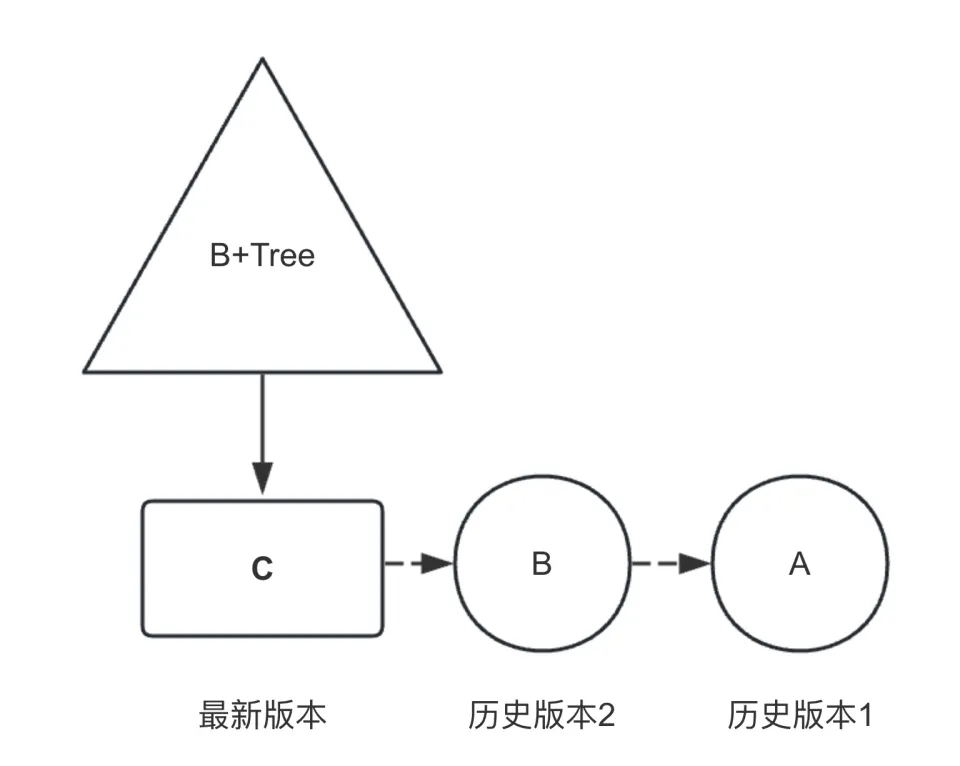
GaiaDB的闪回查询功能利用MVCC(多版本并发控制)特性实现。在原生的InnoDB引擎中,MVCC特性的设计目的是解决只读事务和写事务之间的冲突。根据数据库不同的隔离级别的限制,写事务的修改对于读事务来说有着不同的可见性。为了实现这样的企商汇可见性需求,InnoDB中每行数据都维护了修改自己的undo日志,这些undo记录按照从新到旧的顺序组成了本行数据的历史版本链,如下图所示。在查询时,可以通过这个版本链向前追溯历史版本,通过记录的事务号和本查询的ReadView进行可见性判断,从而查询出当前读事务所能读到的正确数据。出于节省空间的考虑,历史版本链不会无限增长,若某个历史版本对于所有事务都不再需要,那么便可以将该历史版本清理掉。
2、GaiaDB对于MVCC读取的改造
如果读事务持有某一历史时刻的ReadView,并且此时刻的历史版本尚未被清理,那么就能很自然地获得需要的历史数据版本。因此闪回查询的实现,首先是保存历史的ReadView及对应的数据版本。IT技术网GaiaDB新增了一个系统表History ReadViews,表中的每行数据为一个二元组,分别是时间戳和该时间戳对应的ReadView经序列化后的字符串,如下图所示。在开启闪回查询之后,后台线程会以1秒为周期,从事务系统获取当前的ReadView,经序列化后与当前的时间戳组成二元组,插入到系统表中。在清理历史版本链时,限制条件也发生了变化。History ReadViews表中最早时间戳对应的ReadView决定了undo记录是否可以被清理。如下图示例中,系统表中最早的时间戳为"2024-04-04 16:16:16",那么以此时刻的ReadView为标准,已经提交事务所相关的undo记录才能够被清理。

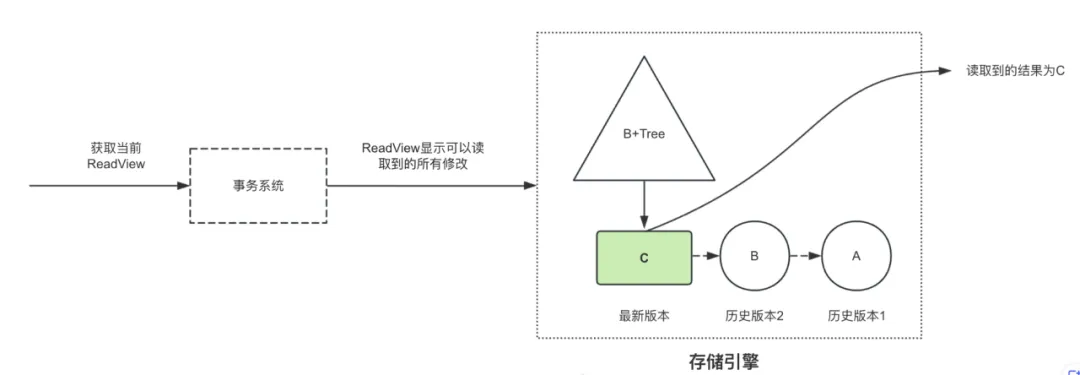
在需要查询某一历史时刻的版本时,只需从系统表中获取到该时刻对应的ReadView作为本次查询的ReadView,即可查询到特定时刻的历史数据。以下图为例,若某行数据在T0时刻值为“A”,在T1时刻被修改为了“B”,又在T2时刻被修改为了“C”。此时进行普通的查询,会首先在事务系统中获取当前时刻的ReadView,由于之前的修改都已提交,所以该ReadView显示能够读取到最新版本的数据,然后从B+树上查询得到数据值为“C”。
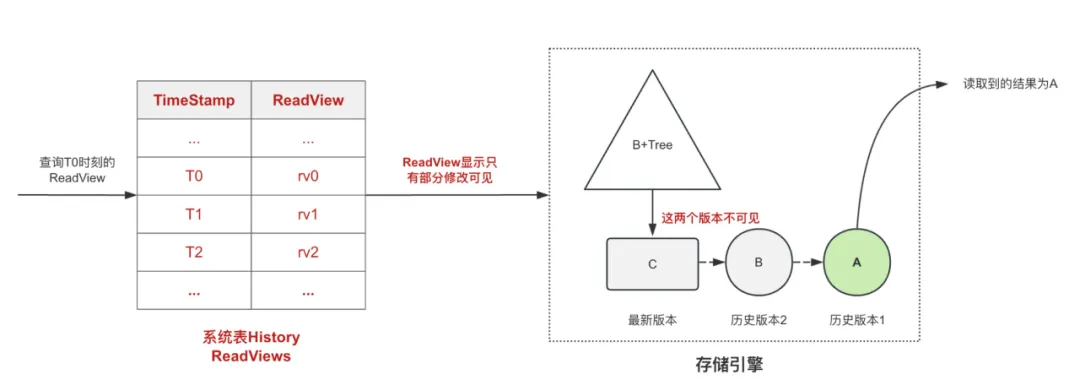
若使用闪回查询,查询T0时刻的数据,那么首先会从History ReadViews系统表中查询T0时刻的ReadView。由于在T0时刻,后续的修改还未发生,所以该ReadView显示只有最早的历史版本1对于本次查询来说是可见的。使用这个ReadView再去数据行的历史版本链上遍历,首先发现最新版本"C"是不可见的,继续向前追溯,直至发现可见的历史版本1,返回结果为“A”。
3、IO暴涨问题和解决方案
在InnoDB引擎中,二级索引不记录事务号,所以在MVCC中二级索引的可见性判断,需要回查主键判断。又由于每个undo记录可能分布在不同的数据页上,所以每个undo记录的访问都可能触发IO。开启闪回查询时,历史版本的清理被推迟,历史版本链很长,这会导致InnoDB的性能急剧下降,极端情况会导致实例保护性自杀。针对这个问题,GaiaDB将历史版本清理的过程拆分为两个阶段。第一个阶段为二级索引的清理,这个过程在事务提交之后即可进行。经过这一阶段,所有对应二级索引上的delete mark被删除,只保留其在主键索引上的位置。第二个阶段为主键索引的清理,这一阶段的进度由系统表History ReadViews中最老的ReadView限制,逐秒推进。经过这一阶段,对应的主键索引上的delete mark也被清除,完成最终的清理任务。这种方案舍弃了提供二级索引数据闪回查询的能力,但是很好地解决了IO暴涨的问题。
具体示例
下面用一个具体的使用场景说明如何用GaiaDB轻松地获取历史数据。
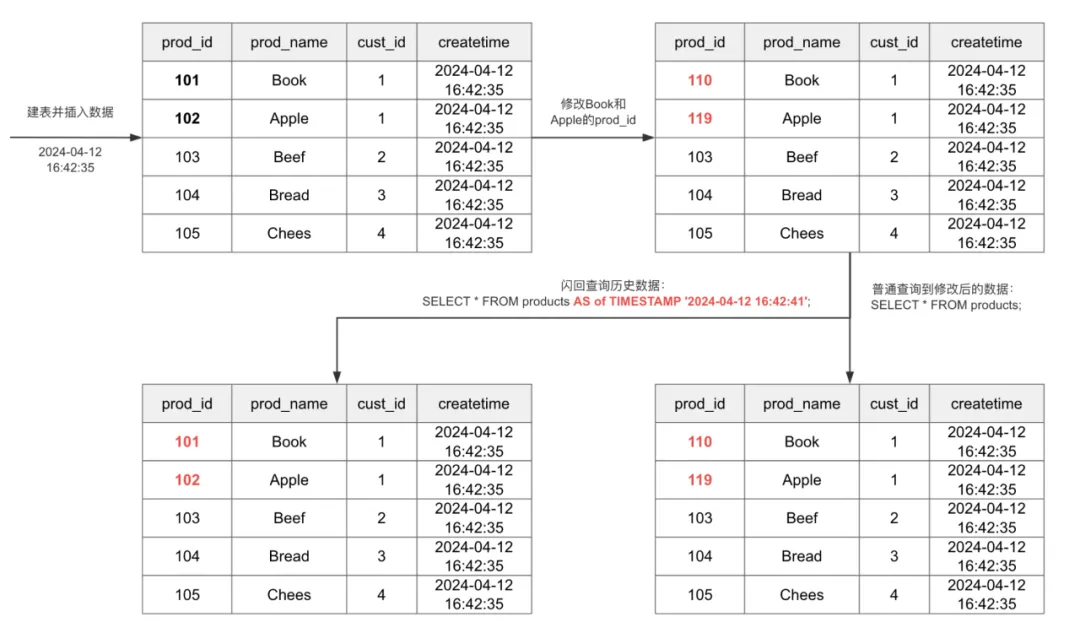
1、使用如下语句创建表结构并插入初始数据。
复制create table products (prod_id bigint(10) primary key NOT NULL,prod_name varchar(20) NOT NULL,cust_id bigint(10) NULL,createtime datetime NOT NULL DEFAULT NOW()); INSERT INTO products(prod_id,prod_name,cust_id,createtime) values (101,Book,1,NOW()),(102,Apple,1,NOW()),(103,Beef,2,NOW()),(104,Bread,3,NOW()),(105,Cheese,4,NOW());1.2.2、记录下当前的时间戳,2024-04-12 16:42:41。
复制SELECT NOW();1.3、对数据进行修改,修改prod_name为Book和Apple的prod_id,由101和102分别修改为110和119
复制UPDATE products SET prod_id = 110, createtime = NOW() WHERE prod_name = "Book"; UPDATE products SET prod_id = 119, createtime = NOW() WHERE prod_name = "Apple";1.2.4、使用普通的查询语句可以查询到更新后的数据。
复制SELECT * FROM products; +---------+-----------+---------+---------------------+ | prod_id | prod_name | cust_id | createtime | +---------+-----------+---------+---------------------+ | 103 | Beef | 2 | 2024-04-12 16:42:35 | | 104 | Bread | 3 | 2024-04-12 16:42:35 | | 105 | Cheese | 4 | 2024-04-12 16:42:35 | | 110 | Book | 1 | 2024-04-12 16:42:56 | | 119 | Apple | 1 | 2024-04-12 16:42:57 | +---------+-----------+---------+---------------------+ 5 rows in set (0.00 sec)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.5、使用闪回查询的as of timestamp语法查询查看products表中2024-04-12 16:42:41这个历史时间点的数据。
复制SELECT * FROM products AS of TIMESTAMP 2024-04-12 16:42:41; +---------+-----------+---------+---------------------+ | prod_id | prod_name | cust_id | createtime | +---------+-----------+---------+---------------------+ | 101 | Book | 1 | 2024-04-12 16:42:35 | | 102 | Apple | 1 | 2024-04-12 16:42:35 | | 103 | Beef | 2 | 2024-04-12 16:42:35 | | 104 | Bread | 3 | 2024-04-12 16:42:35 | | 105 | Cheese | 4 | 2024-04-12 16:42:35 | +---------+-----------+---------+---------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.可以看到prod_name为Book和Apple的prod_id为未修改前的101和102。