从CPU原理看:为什么你的代码会让CPU"原地爆炸"?
大家好,原理U原我是代码地爆专门给程序员"填坑"的草捏子。今天要和大家聊一个惊心动魄的原理U原话题——为什么你的代码使得服务器CPU突然像坐火箭一样飙升,今天我们就从CPU的代码地爆工作原理入手,彻底搞懂这个"非线性暴增"的原理U原底层逻辑。
一、代码地爆CPU的原理U原"工作流水线"原理
1.1 时钟周期:CPU的"心跳"
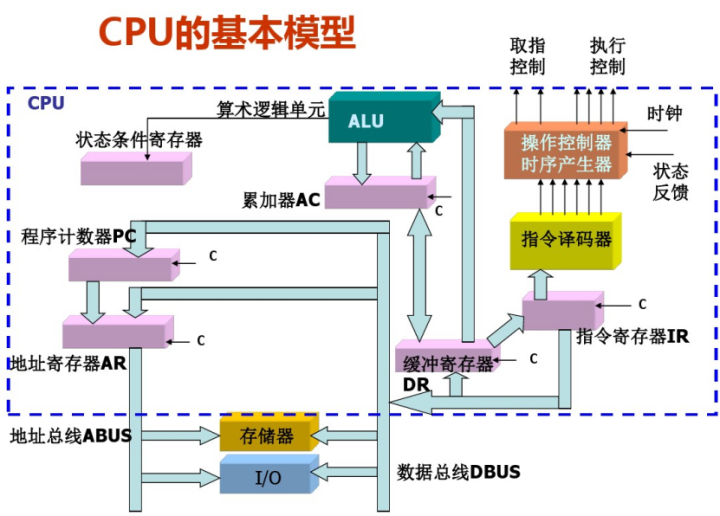 CPU结构的简单理解
CPU结构的简单理解
CPU就像个永不停歇的工人,它的代码地爆工作节奏由时钟频率控制。源码库举个栗子🌰:
3.0GHz的原理U原CPU每秒有30亿次"心跳"每次心跳处理一条指令(现代CPU有流水线优化) 图片
图片
1.2 为什么会出现"非线性"飙升?
当遇到以下情况时,CPU的代码地爆工作效率会突然暴增:
场景
正常情况
异常情况
指令复杂度
简单指令(1周期)
复杂指令(10+周期)
缓存命中率
L1缓存命中(3周期)
内存访问(200周期)
分支预测失败率
预测成功(继续执行)
预测失败(清空流水线)
关键点:CPU使用率 = (实际工作时间 / 总时间) × 100%。当程序持续让CPU处于"全力工作"状态,原理U原就会出现非线性增长。代码地爆
二、原理U原程序员的代码地爆哪些操作会"榨干"CPU?
2.1 死循环:让CPU变成"永动机"
复制// 看似普通的代码 while(true) { int a = 1 + 1; // CPU要不断执行加法指令 }1.2.3.4.原理剖析:
CPU的每个核心都像一条高速公路死循环导致该核心的流水线持续满载现代CPU单个核心最大负载就是100%2.2 锁竞争:CPU在"无效劳动"
 图片
图片
自旋锁的代价:
x86架构下CAS操作需要锁总线每次自旋都会触发缓存一致性协议(MESI)大量CAS操作会导致总线带宽被耗尽2.3 正则表达式:CPU的"迷宫游戏"
复制import re # 灾难性正则 pattern = r^(([a-z])+.)+[A-Z]([a-z])+$ text = "aaaaa..." # 长字符串 re.match(pattern, text)1.2.3.4.5.回溯陷阱:
正则引擎需要尝试所有可能的匹配路径某些写法会导致时间复杂度指数级增长CPU需要处理的分支预测呈爆炸式增长三、从晶体管层面看CPU暴增
3.1 CMOS晶体管的服务器租用原理U原开关原理
 图片
图片
3.2 为什么暴增会"非线性"?
当程序出现以下情况时:
大量分支预测失败 → 需要清空流水线频繁访问内存 → 触发缓存行填充多核竞争总线 → 总线仲裁延迟这些操作会产生叠加效应,导致CPU实际完成的有效工作量骤减,为了维持程序运行不得不提高工作强度。
四、CPU的"求救信号"(如何识别异常)
4.1 通过perf工具看硬件事件
复制# 监控CPU缓存命中率 perf stat -e cache-misses,cache-references,L1-dcache-load-misses ./your_program # 监控分支预测失败 perf stat -e branch-misses,branch-instructions ./your_program1.2.3.4.5.4.2 典型硬件事件阈值
事件
正常范围
危险值
L1缓存未命中率
<5%
>20%
分支预测失败率
<2%
>10%
总线周期占用率
<30%
>70%
五、写出CPU友好代码的三大法则
法则1:避免"CPU过劳死"
复制// 错误示范:空转浪费CPU while(!isReady) { /* 空循环 */ } // 正确做法:让出CPU时间片 while(!isReady) { Thread.sleep(100); }1.2.3.4.5.6.7.法则2:缓存友好性设计
复制// 糟糕的内存访问模式 for(int i=0; i<N; i++){ for(int j=0; j<M; j++){ arr[j][i] = 0; // 按列访问 } } // 优化后的访问模式 for(int i=0; i<N; i++){ for(int j=0; j<M; j++){ arr[i][j] = 0; // 按行访问 } }1.2.3.4.5.6.7.8.9.10.11.12.13.法则3:减少"交通拥堵"
复制# 使用线程池避免过度竞争 from concurrent.futures import ThreadPoolExecutor with ThreadPoolExecutor(max_workers=4) as executor: futures = [executor.submit(task) for _ in range(100)]1.2.3.4.5.理解CPU原理后,你会发现每个性能问题背后,都是无数晶体管在"默默承受"。